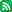그럼 다시 원자와 쿼크의 관계처럼 픽셀에 대해서도 정리해보자. 그러면 아마도 ‘하나의 픽셀은 빛의 삼원색을 나타내는 더 작은 요소로 되어 있고, 그 요소들의 가산 혼합에 의해 하나의 픽셀의 색을 결정하게 된다’라고 내용을 정리할 수 있을 것이다. 그렇다면 문제는 그 요소들이 어떤 식으로 배열이 되어 있냐는 것인데… 그것이 이 강좌의 핵심적인 부분을 이해하는데 필요한 내용이다.
3. 픽셀 구조의 이해
모든 강좌에서 남을 가장 쉽게 이해시키는 방법은 직접 눈으로 보여주는 것이다. 내가 이야기 하고자 하는 것을 쉽게 이해 시키기 위해 사진 하나를 첨부했다. (NDS 화면이다)
<사진>
왼쪽에는 보라색 선이 세로로 2개가 있고, 오른쪽에는 보라색 선이 세로로 3개가 있다. 그런데 여기서 왼쪽이 일반적인 보라색을 출력한 것이고 오른쪽의 것은 실제로 세로 2픽셀의 영역에 3개의 선을 보이게 한 것이다.정확하게 이야기 하면 중간의 선은 실제로 어느 픽셀의 소속이라고도 말하기 어려운 상태이다. 그러면 어떻게 이렇게 되는지 다음 그림을 보면 이해가 될 것이다.
왼쪽의 그림은 픽셀 구조를 확대해서 그린 것이고 오른 쪽의 그림은 설명을 위해 약간의 부가적인 정보를 추가했다.
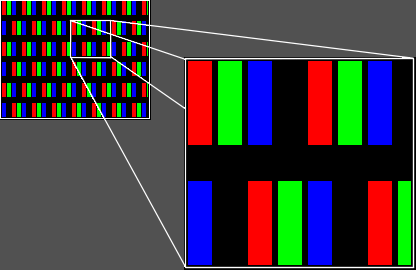
우리는 빨간색과 파란색을 섞으면 보라색이 된다는 것을 알고 있다. 그래서 일반적인 프로그래밍으로 보라색을 표시하면 왼쪽의 선과 같이 출력이 된다. 하지만 빛의 합성 원리 입각해서 보면 (1)도 보라색으로 보이지만(2)도 보라색으로 보여야 한다. 오히려 보라색의 경우에는 이렇게 어중간한 픽셀에 만든 선이 더 보라색에 가깝다. 실제 병치 혼합되는 거리가 가깝기 때문이다. (눈으로 직접 봐도 같은 결과다) (2)의 부분은 실제 8번 픽셀과 9번 픽셀의 경계를 걸쳐 형성되었는데 이렇게 만들려면 8번 픽셀은 파란색, 9번 픽셀은 빨간색으로 출력해야 한다.
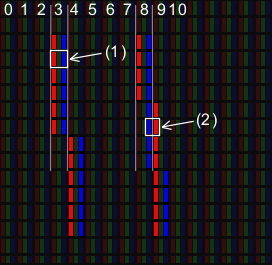
방금 보라색의 예를 들어 보았다. 그렇다면 흰색의 경우는 어떨까. 흰색은 빨간색, 녹색, 파란색이 모두 가장 밝은 상태가 되면 만들어진다. 위의 보라색의 예와 같이 픽셀의 경계를 무너뜨리게 되면 다음과 같은 조합도 모두 흰색이 된다.
(1)은 평범하게 3x3의 흰색을 출력했을 때의 결과다. 그리고 (2)는 청록색-흰색-흰색-빨간색의 4x3을 출력한 것이고, 마지막 (3)은 파란색-흰색-흰색-노란색의 4x3을 출력한 것이다. 그런데 이 3개의 사각형은 모두 흰색의3x3으로 보인다. 좀 더 자세히 설명하자면, (1)은 RGB-RGB-RGB로 3개의 점을 나타내고, (2)는 GBR-GBR-GBR 로 3개의 점을 나타내고, (3)는 BRG-BRG-BRG로 3개의 점을 나타내기 때문에 사람의 눈으로는 모두 흰색으로 보이는 것이다. 단지 이 3개의 다른 점이라면 (2)와 (3)은 정확하게 픽셀에 딱 맞게 떨어지지는 않는다는 정도인데 이러한 편법을 적당히 이용하여 실제 해상도의 한계보다 더 많은 표현 하게 하자는 것이 이 강좌의 핵심이다.
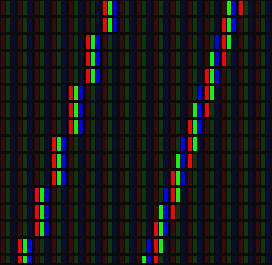
그렇다면 이번에는 이 편법의 극적인 효과를 확인하기 위해 y = 3x의 그래프를 한 번 그려보자.
왼쪽은 이전 방식으로 프로그래밍했을 때이고, 오른쪽은 픽셀의 경계를 넘어가면서 그렸을 때의 결과이다. 화면이 마치 가로로 3배의 해상도를 더 가진 것처럼 보인다. DPI(dots per inch)가 큰 경우는 이상하게 보일지는모르겠지만 DPI가 작은 소형 게임기나 휴대폰 등에서는 마치 그 사이에 픽셀이 더 있는 것처럼 보인다. (Bresenham의 line 그리기 알고리즘도 이 편법으로 개선 시킬 수 있다.)
이제 사전 지식도 완벽하고 이 방식을 사용했을 때의 이점도 명확해졌다. 그렇다면 이것을 어디에 적용할 수 있는지를 생각해볼 차례다. 물론 그래픽 디자이너에게 이 방법을 알려줘서 256*192 해상도에서도 더 나은 퀄리티를 내게 할 수 있을는지도 모르겠다. 하지만 이 방법은 단점도 매우 많기 때문에 생각만큼 많은 곳에 응용되지는 못한다.
내가 생각한 최고 응용 법은, 이것을 통해 anti-aliasing 처리를 많이 줄일 수 있을 것이란 생각이다. 사실 anti-aliasing은 품질을 좋게 하기 위한 방법인데 왜 그걸 줄이느냐고 반문할 사람이 있을 수도 있겠다. 하지만 anti-aliasing은 ‘좋지 않게 된 품질’(alias가 있는)을 좋은 것처럼 보이게 하는 눈속임일 뿐이다. 그래서 가장 좋은 방법은 처음부터 alias를 만들지 않는 것이다.
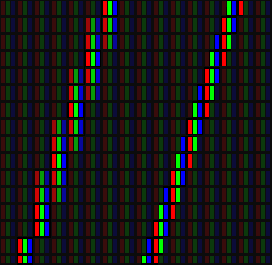
그러면 역시 그림을 통해 그 결과를 확인해 보자.
왼쪽의 선은 y = 3x의 그래프에 anti-aliasing을 집어 넣은 것이고 오른쪽의 선은 픽셀 간 경계를 넘어선 방식이다. (모니터를 멀리하고 떨어져서 보면 두 선의 차이가 구분이 될 것이다)
간혹 ‘그렇게 보았더니, 왼쪽의 선은 무채색으로 보이는데 오른 쪽은 그렇지 않다’라고 생각하는 분도 있을 것이다. 하지만 제대로 본 것이다. 위처럼 픽셀을 크게 만들어 놓으면 녹색이 강조되기 때문에 선이 녹색 기준으로 보일 것이다. 이것은 인간의 시신경의 추상체가 RGB의 휘도를 동일하게 감지 하지 않는 것에 그 이유가 있고, 그것까지 고려해서 오른쪽 선을 그려야만 진정한 편법이 완성 되는 것이다.
4. 제약 사항
지금까지는 응용 가능한 부분에 대해서 이야기를 했지만 이번에는 제약 사항에 대해서 알아 보자.
- LCD가 아니면 효과가 좋지 않다. PDP 판넬의 구조를 보면 LCD와 좀 다르다. (제조사마다 다르지만)
- 자신이 적용하고자 하는 디바이스의 LCD 구조에 맞게 구현이 수정되어야 한다. (NDS용이라면 좀 달라져야 한다)
- 검은 바탕에 흰 무엇 또는 흰 바탕에 검은 무엇을 표현할 때 효과가 크다.
소형 디바이스라면 대부분 LCD이겠지만 LCD의 pixel 구성 요소의 배열 구조는 제조사마다 다르다. 그러므로 그에 맞게 구현이 달라져야 하며, 설령 배열 구조는 같더라도 pixel과 pixel 사이의 간격이 큰 LCD라면 역시 적용이 불가능 하다. 또한 CRT나 일부 PDP의 경우에는 각 픽셀이 사각형의 격자 형식으로 빼곡히 들어가 있는 것이 아니라 interlace 단위로 서로 엇갈려 있는데, 이 경우도 적용이 불가능 하거나 적용 방식이 달라져야 한다(제일 처음 언급한 이코노 칼라 텔레비전의 구조를 생각하면 된다)
이 강좌의 처음에서, 정보 전달의 요소는 ‘이미지’와 ‘글자’라고 했다. 그리고 우리의 최종 목표는 이 ‘이미지’와 ‘글자’에 대해, 제한된 자원에서 최대한 많은 정보를 전달 할 수 있게 하는 것이다. 그럼 이 요소들에서 어떤 부분을 개선할 수 있을까? 위의 강좌 내용만 갖고도 생각할 수 있는 것은,
‘이미지’
- 축소 scaling을 할 때 더 세부적인 위치 정확도까지 묘사할 수 있다.
- 스프라이트가 더 세부적인 단위로 움직일 수 있다.
‘글자’
- Anti-aliasing 없으면서 alias 없는 출력을 할 수 있다.
- 더 작은 해상도에서도 가독성 있는 글자를 출력할 수 있다.
예로서 2가지씩만 들어 보았는데, 나머지는 당신의 창조적인 아이디어로 채워보자.